分布式存储研发(块存储方向 / kv 方向 / 数据库内核方向) |
您所在的位置:网站首页 › 存储研发 职业前景如何 › 分布式存储研发(块存储方向 / kv 方向 / 数据库内核方向) |
分布式存储研发(块存储方向 / kv 方向 / 数据库内核方向)
|
文章目录
2年经验 面试准备2年经验 面试问题深信服(ceph存储研发)旷世科技(ceph存储研发)百度 基础架构部(分布式存储研发工程师)快手(基础架构:分布式存储研发工程师)金山云(分布式文件系统研发)阿里云(polardb 分布式存储研发)
4年经验1. 编码2. 项目方向3. 分布式方向4. OS方向
本人从2020. 2.16号疫情期间开始投递简历到3.30结束找工作,基本面试了所有的大厂(互联网公司/科技公司)。面试的过程很艰辛,发现了很多不足,但是也收获到了满意的offer,特此做一轮总结,方便后续的伙伴参考借鉴。
2021.2.7 更新 后续会持续补充面试过程中的问题答案,希望能够帮助到大家。 同时针对如下提到的存储技能树,也欢迎大家一起补充,相关原始文件xmind有对应的github链接。 2年经验 面试准备分布式存储系统知识准备。以下我的分布式存储技能树 以及 相关的知识图谱 可以借鉴一下。 这个知识图谱比较关键,因为分布式存储的知识图谱过于庞大,想要比较好的掌握,一定需要形成属于自己的知识框架才行。 分布式存储(ceph) 方向 技能图谱 比如 下面是我的ceph 技能分支: 针对性准备。 boss/脉脉/猎头之类的发送的岗位要求,一定针对性的每一个要求都要准备充分。 比如: 要求一: 掌握基本的设计模式,熟悉基本的数据结构和算法。 至少单例,工厂,建造者,代理等这样的常见设计模式就需要非常清楚 其特点,应用场景,以及能够快速写出一个简单的示例。基本的数据结构和算法:链表/队列/栈/二叉树 这样的基本数据结构要非常熟悉,手写每个都要能够快速且bug-free;还有常见的算法,上面我的技能树中也有列,可以参考一下。比如: 要求二:熟悉leveldb/rocksdb实现,有大规模分布式 NoSQL 开发经验 那就需要真正得看过底层的源代码(至少关键模块的:Put/Get链路, flush/compaction),直到其在业界的定位,什么场景用什么样子的配置更好,对于不同的workload 有没有好的优化手段(读写放大,compaction I/O影响读延时 等) 2年经验 面试问题面试的公司包括 深信服、旷世科技、滴滴 、百度 (基础架构部)、阿里(polardb 分布式存储研发)、金山云、快手、BIGO、头条、华为(公有云) 岗位:分布式存储研发工程师,我个人毕业后两年内从事的是ceph存储系统的运维和开发(其实水平远远达不到开发的程度,毕竟只有不到两年,都没有向社区commit过代码) 深信服(ceph存储研发)深信服一面(深信服有较强的ceph研发背景,如果各位没有深入到底层代码,建议不要轻易尝试,否则会被怼) 自我介绍项目介绍 --30分钟bluestore状态机的实现bluestore如何保证数据一致性;bluestore的有那些回调,分别是用来做什么的bluestore wal事务都具体包括哪一些内容(详细信息)当数据落盘 但是元数据还未落盘,存储下电是否会对数据一致性有影响(考察bluestore的写流程:数据和元数据的写)当数据未落盘,客户端触发针对改对象的读请求,是否能正常读出pg状态机用来做什么,为什么要有状态机pg状态机中post_event(),discard_event分别是用来做什么的bluefs 元数据文件的保存方式,存储在哪里,加载方式db分区中的.log和.sst文件分别保存了什么cache-tier有哪一些模式,各自功能是什么,有遇到什么问题吗(他们提交的一个cache tier的bug-fix,好像在write-back模式下有数据一致性问题)在EC 模式下,数据怎么分片;EC 和 副本模式区别是什么操作系统IO栈简单讲一下,每一层都是做什么的sync和direct有什么区别如果对同一个设备文件分别使用direct和sync方式打开会有什么影响线程间同步方式多线程 条件变量中pthread_cond_wait参数为什么要传入一个mutex互斥变量一面的话整体还是能感觉到深信服ceph做的还是比较深入,毕竟有不少参与社区贡献的人员。 深信服二面(leader面) 自我介绍项目介绍 – 20分钟bluestore 状态机有哪一些线程,每个线程都在做什么(感觉他们非常看重ceph底层核心实现)社区源码贡献了多少行自己修改源码多少行,做了哪些改动,核心功能是什么整体感觉他们还是更看重CEPH的核心研发经验,对底层编码以及操作系统基础并未关注太多 旷世科技(ceph存储研发)旷世一面 自我介绍+项目介绍 30分钟bluestore写机制(simple + deferr 分别描述一下)bluestore怎么保证数据一致性pglog的作用peering的过程,每一个状态都在做什么ceph整体可靠性的体现操作系统IO栈优化思路(我简历写了熟悉IO栈的优化)通用块层做什么,有哪一些调度算法,每个调度算法讲讲,分别用在哪一些场景旷世二面 自我介绍+项目介绍 10分钟写算法:给定一个数,求其2进制中1的个数 (位运算)写算法:求一个无序数列中第K大的数,时间复杂度要求O(n)。 开始想了最小堆O(nlogk),后来提示快排可以,写出来了ceph 的可靠性怎么体现(正常写时的可靠性,出现节点冗余时的可靠性)ceph 负载均衡怎么实现(crush算法)旷世三面 自我介绍+项目问题 30分钟Linux IO栈 架构讲讲ext4文件系统介绍一下,inode,dentry的管理方式虚拟进程内存分布物理内存和虚拟内存怎么进行映射(内存管理中的页表实现)写算法:给定一个无序字符串“aa.b…c/.d” ,将其组合成linux可以访问的目录输出(只要输出一个即可)旷世四面(leader面) 项目题问 20分钟linux内存管理机制(进程虚拟内存–》页表–》物理内存,高速缓冲区(buffer,page cache),内存分配机制,回收机制)熟悉内存优化是吧,讲讲内存问题怎么排查,常用的工具,有哪些优化思路怎么获取这一些知识的,有线上实践过吗,举个例子。。。一堆技术无关的旷世有四轮技术面试,这还是让我很惊讶,总体感觉旷世的CEPH积累显然没有深信服足,毕竟他们的存储只是给他们深度学习平台做数据处理和加工的,并没有相关的存储产品。 百度 基础架构部(分布式存储研发工程师)百度一面 项目介绍+ 提问30分钟CEPH的负载均衡实现(crush算法的实现)有什么方式能追踪一个IO从客户端到磁盘过程ceph怎么保证高可靠性(主要问 集群有节点异常时数据的恢复方式 ,是否能对外提供正常的读写请求)EC 和 副本的区别Linux内存管理机制段式内存管理和页式内存管理区别进程内存分布cache是怎么实现的,用什么数据结构(read系统调用的实现过程)buffer cache和page cache的区别讲讲你的内存优化思路C++ static关键字的作用C++类实例化的过程,构造函数压栈都有哪一些参数多态怎么实现的智能指针有哪些,分别用在什么场景,shared_ptr循环引用问题怎么解决写算法:Z字型打印二叉树(二叉树的层序遍历做一些修改)有什么想问的吗,简单介绍了一下百度基础架构部的自研文件系统架构,规模,发展方向百度二面 项目介绍 + 提问 30分钟bluestore写方式,元数据包括哪一些bluestore cache怎么实现的,管理哪一些内容CEPH怎么保证数据一致性CephFs的实现(mds的inode,dentry管理方式,mds的负载均衡实现)cephfs怎么保证数据一致性(IO正在落盘,但是mds所在节点异常时)Linux IO栈优化思路讲讲写算法:合并k个有序链表写代码:根据实际场景出的一个类的设计代码(主要是考察map)百度三面(leader) 项目+提问 20分钟Linux IO瓶颈分析使用哪一些工具,怎么分析通用块层的作用?哪一些调度算法,分别做什么?怎么做IO合并项目中遇到哪一些问题,怎么解决的,难点是什么?职业规划。。。期望薪资,什么时候能入职百度的面试体验很不错,面试的过程比较专业,而且效率也很高 只是技术面之后的HR面流程太长,效率太低了。 快手(基础架构:分布式存储研发工程师)快手面了两个岗位,第一个是高级研发(后面因为能力不匹配被拒了,自己失误,显然能力不匹配呀),第二个是比较契合的研发工程师岗位 高级研发岗位(ceph方向) 一面 项目+提问 20分钟 ceph-fuse 和 fuse的区别 数据从cephfs 到落盘的 过程,ceph-fuse怎么处理 cephfs 元数据管理机制 mds的active+active模式 和 active+stand by模式的区别,当有主mds所在节点异常时怎么保证cephfs的正常服务,数据可靠性怎么保证 read系统调用的实现 简单讲讲 linux内存管理机制 malloc和free的区别 大页表的实现,用在什么场景 OOM机制 讲讲 ext4文件系统懂吗?讲讲(只能说一下inode和dentry的管理方式) inode,dentry,superblock 各自有什么用,有什么联系?怎么查看以上三者? 写算法:非递归后序遍历二叉树 二面 项目+提问 20分钟觉得ceph有什么问题?cephfs使用的时候有什么问题?ceph-fuse实现cephfs处理大量小文件写的时候是否有性能问题?卡在了哪里?是否尝试过优化?peering过程说一下,主要哪几个状态,每个状态做什么事情数据库的ACID 属性 讲讲B+树了解吗,基本原理是什么linux 文件系统IO流程写算法 :给定一个数组,求其中三数之积最大的值 (leetcode原题)。要求:时间复杂度优于O(n^3)二面之后就因为个人面试中并没有太突出的表现,约了三面,后面因为面试官较忙,同时综合评估能力未达到高级的程度就拒了,接下来内推了快手的中级别研发岗位:分布式存储研发工程师 分布式存储研发 岗位 一面、二面、三面基本和之前的技术方向接近 差异的问题如下: 写算法:给定一个无序的数组,有正有负,求最大的子序和,以及该子序的起始下标。–简单动态规划,可以看leetcode的动态子序和写算法:层序遍历二叉树C++ const 关键字的用法,修饰类的成员函数有什么作用内联函数和define宏定义的函数有什么区别new的过程,new的返回值,malloc的内核态过程,malloc的返回值(成功返回什么,失败返回什么),new和malloc的区别设计模式了解吗?单例模式和懒汉模式的区别,工厂模式用在什么场景(建议23种设计模式都过一遍)一台设备,1G的内存,怎么实现10G数据的排序(我能想到的就是分治了)快手整体面试效率很高,如果你时间充足,可能就是连续的三轮技术面试。 面试官也很nice,对于一时回答不上来的会给你提示,并且会和你一起探讨解决办法,并不会表现出不屑或者不耐烦的情绪。后续的HR沟通反馈效率也非常高,有问必答那种。 PS:快手福利待遇相当不错! 金山云(分布式文件系统研发)金山云 一面 项目+提问 20分钟cephfs实现原理cephfs元数据管理方式,inode和dentry是怎么管理的,如果主mds所在节点异常了cephfs怎么保证高可靠性ceph mds负载均衡怎么实现TCP连接可靠性的体现(3次握手、4次挥手),怎么实现数据包的保序,流量控制和拥塞控制的区别DHCP 服务的作用arp协议的作用,网络通信中什么时候会用到arp协议怎么检测网络是否达到瓶颈(netperf、ifstat)常用的路由算法有哪些,各自怎么实现最短路由的linux内存管理讲讲,怎么确定内存瓶颈?怎么进行优化?swap的作用是什么,什么时候会用到swap,优劣是什么数据库了解吗?(分布式存储基本没接触过数据库,表示只知道ACID属性)ACID中 隔离性是怎么实现的(这里脏读、幻读之类的描述了一下,从熟知的ceph bluestore层描述了一下隔离性的实现)写算法:给定一个链表,两辆反转,输出反转后的结果思考题:如何证明连续的三个数之积能够被6整除(数学归纳法)金山云 二面(现场面–好像直接就leader面了) 项目+题问 20分钟ceph高性能,高可靠性的体现(从集群正常、集群节点异常两个场景说明)Linux IO栈优化思路讲一下(性能指标–》性能工具–》性能瓶颈–》IO栈每一层的基本优化方法)IO调度算法有哪些,分别用在什么场景数据库有了解吗?(ACID属性)B树和B+树的区别(不了解)后面介绍了一下部门情况,业务发展之类的金山云 的公有云 市场份额在不断被阿里云,华为云,腾讯云 大头挤压,竞争力不是很强。 个人感觉金山云技术还行,但是还没有快手、百度这种互联网公司的基础技术雄厚,分布存储也是比不过阿里、深信服这种专门买存储系统的,个人建议。 阿里云(polardb 分布式存储研发)阿里云一面 (凉凉,总结下来就是no zuo no die,在真正的大佬面前还是规规矩矩的好) 项目介绍 + 提问 20分钟(讲项目的过程中会打断,题问感兴趣的点)快照的原理是什么,快照过程中都有哪一些数据做备份,元数据在快照过程中起什么作用(自己当时根本不了解快照的,),悲剧就此展开EC原理是什么,EC和副本的区别,EC可靠性和副本可靠性的差异(都得实现6个9及以上的可靠性),为什么你们会选择副本模式做cache tier你们代码架构的都是怎么设计的,怎么实现功能的添加修改而不影响其他功能(代码设计模式)CEPH可靠性的实现(bluestore层),正常接收IO时节点异常,ceph怎么保证可靠性你负责的最有挑战性的任务时什么,遇到过哪一些困难,怎么解决的,完成计划是如何安排的这个时候其实已经感觉凉凉了(阿里一面主要是部门内部的研发人员面试,这次面试因为作了一下,完全将自己的劣势体现出来,而面试官感知能力极强,立即发现自己讲的有一些不太清楚,接下来就穷追问底,真是极大的失误)。总体总结下来自己还有很多方面不足: 分布式存储系统底层实现细节还差很多(快照、数据一致性在存储引擎bluestore的实现)—如果有机会接触自研存储系统,需长时间的积累沉淀,挖掘系统内部核心技术(流控,负载均衡,数据可靠性。。。)的实现编码:设计模式欠缺较多(23种设计模式得一点一点梳理,熟悉,应用),算法能力需持续提高(需后期的工作中刻意练习)操作系统各个子模块实现网络协议应用—实现路漫漫兮其修远,分布式存储技术 仅仅是分布式技术中的一个分支,仍需加油努力,用鲁棒的基础搭配庞大且结构化的知识,持续精进总结,一定能够登顶分布式高峰。 4年经验近期因为个人原因又开始考虑换工作的事情,具体原因就不展开了。 因为个人近两年的主要方式是单机存储引擎,所以本次期望的方向主要是稍微偏上层的一些,像是数据库内核研发。 先简单描述一下 存储岗位的分类,从存储数据的形态上来看 大家比较公认的是结构化存储 和 非结构化存储。 结构化存储 主要是一些拥有数据格式的系统的存储服务,像是 分布式图存储(nebula),k/v 存储(单机 leveldb/rocksdb等等 /主从 redis ,pika这种 nosql ),文档存储(mongodb), 关系型数据库(mysql, tidb,oceanbase 等等),时序数据库(clickhouse 等) 或者 基于云原生的 数据仓库。 非结构化存储 ,存储系统不感知用户的数据类型,分布式文件系统,分布式块存储,分布式对象存储 ,其中ceph 比较有代表性,以及像是smartx 做的超融合系列的私有云存储。 我所选择的方向其实是在结构化存储领域中,希望能够在这个领域中再持续扎根。其中的每一个方向都有其特有的设计,像是单机以及分布式形态的 以上类型大多底层存储是 shared-nothing,也就是每一个分布式节点是占用一个实际物理机器 ,这样的架构是性能最为有好的,然而成本也是最为昂贵的;所以在存储架构上,大家都希望能够支持存储上云 以及 计算 资源和云相结合,底层存储不再是单机存储,而是使用云上的共享存储,计算资源能够根据用户的需求弹性扩缩容,这样就能够在用户体量较为庞大的情况下 有效降低存储成本,这个方向也是现在的结构化存储 中的分布式应用中大家持续探索落地的方向,更是卷出天际的方向。 我个人还是希望能够利用好这个风口,跟着风做一只快乐飞翔的猪。 想要利用好这个风口,一些准备还是必不可少的。 所以接下来说的面试的公司以及岗位基本都是以上 结构化存储领域中的某一个子分支的方向,这里就不再提具体公司的名字以及提的问题了,总体上来说是大同小异,分为如下几个方向: 1. 编码这个方向是最为基础的,也是每一个靠谱的公司会持续考察的一个方向,如果你面试的公司在整个面试流程中没有考察到这个基本的能力,那在最后的选择上还是要慎重一些(当然,我说的是4年经验及以下对应的岗位,高阶岗位可能不需要体现这个能力的)。 以下题目是面试公司的汇总,平均每一轮面试都会有一道代码题目: 算法相关: 一个菱形二维数组(一个三角形 + 倒三角形),每一次移动只能向当前顶点的下一个左边或者右边顶点移动;求从菱形的上顶点的数字开始 到菱形的 下顶点为止的最小路径和(仅需要输出最小和即可),主要考察贪心,然后会让你手动构造这个菱形输入 。 类似题目:https://leetcode-cn.com/problems/IlPe0q/二叉树的左视图(层序遍历即可,或者 递归稍麻烦一些)。把一个整数数组 分成两个和相等的子集。(leetcode 原题 没做过,动态规划什么的 – 我没用动归,直接暴力枚举)给定一个整数数组,返回一个同样大小的数组,其中每一个元素代表初使数组中后面元素中 第一个比 对应位置的元素大的元素下标,没有则用 -1 表示 。比如 :输入 [4 2 1 3 7 6 4] , 返回 [4, 3, 3, 4, -1, -1, -1] (双指针 或者 单调栈)B+树的插入流程,实现一个插入函数即可(需考虑分裂 以及 合并的情况 – 伪代码也可以)。堆排序的实现 以及 可以优化的地方(对于每一个插入的元素,在初试堆构造好之后,插入的元素先比较,确定位置之后再插入,同时应尽可能减少整个堆内部其他元素的移动)。最不想淘汰人的 反转链表 …总体来说算法并不是存储岗位的强需求,仅仅需要一些基本算法能力即可,不过该刷的题还是得好好刷一下,逻辑思维能力需要集中训练,如果个人有坚持练习的习惯,那肯定会更好了。 场景/设计题目: 这个方向考察的代码基本能力,总体是偏多的。 实现一个基本功能的线程池。 class ThreadPool { public: ThreadPool(int pool_size); void Add(std::function func); }用条件变量实现一个读写锁,即 读读互不影响,读写阻塞, 写写阻塞。 给定一个迭代器数组std::vector iterator_vecs,要求实现一个 MergeIterator类,其中 有两个操作: T GetCurrent() 获取当前元素,顺序是从小到大;以及 bool MoveNext(),Move之后需要能够返回true/false 标识当前迭代器是否已经到了末尾了。 其实就是leveldb / rocksdb 的 MergingIterator 的超简略版本实现(最小堆内部 放置 迭代器,并写一个支持迭代器的 comparator即可)。 template class Iterator { public: T GetCurrent(); bool MoveNext(); }; template class MergeIterator : public Iterator { public: MergeIterator(std::vector iterator_vec); T GetCurrent(); // your code bool MoveNext(); // your code }使用 void atomic_set(int ele), void atomic_get(int ele), bool atomic_CAS(int ele, int expect) 三个操作实现一个多生产者 单 消费者模型,不能使用锁操作(我是用三个操作实现了一个spinlock,作为锁来用的)。 实现字符串的编码 和 解码方法,不能使用额外的分隔符。(rocksdb/leveldb 的GetLengthPrefixedSlice / PutLengthPrefixedSlice 方法,需要考虑大小端)。 还有一些小型的字符串拼接设计题目,总体编码的难度还好。 2. 项目方向这个方向一定需要认真仔细准备,且准备前需要明确自己接下来所要寻找的方向和项目的方向是有关联的,关联性越大即 岗位职责越匹配,那么项目这里简历上的内容被认可度也会越高。 项目匹配度非常重要。 比如 你的项目是 nosql 分布式k/v 以及 单机k/v 相关联的,那么你寻找分布式图存储/分布式表格存储/数据库内核存储 研发岗位就相对匹配度会高很多,而如果寻找的是云原生数据库内核存储相关的岗位,因为其底层存储设计相比于 nosql 系统来说差异还是比较大的,这样岗位匹配度就会有下降。 因为岗位匹配度足够高,公司有你的加入能够节省非常大的培养/学习成本,能够快速创造收益,这就相比于其他人来说就有很大的优势。 项目架构 以及 实现细节非常重要。 注意,写在简历的存储项目 一定是需要非常清楚上下游的。即 上层应用(设计背景),基本架构 及 架构下面的每一个模块的实现原理 及 作用。 这一些信息 是能够清晰展示个人所在上家公司 的工作难度,个人对项目存在与否的定位是否清晰,是否有主导或者参与到项目中, 是否有独立思考 解决 复杂问题的能力 以及 个人的基础知识是否扎实。都能够在几个简短的项目提问中得到体现。所以,写入到简历中的信息一定是个人能够自圆其说的东西。 比如项目中写了一句简单的话:底层存储使用的是rocksdb 存储引擎。 那么问题就来了: 为什么选择 Rocksdb 存储引擎?业界是否有其他的开源的成熟的存储引擎可以使用?(核心技术选型的时候前期是否有足够多的调研、分析、测试等等)项目中使用Rocksdb 过程中遇到过什么痛点问题(基础的write-stall/调参数可以简单带过)?如何解决的?是否有更好的办法解决?这个过程中你起到什么角色?Rocksdb 存储引擎本身设计出来是为了解决什么问题?和LevelDB的核心差异是?底层的Compaction 核心作用 以及 其存在的问题?当然,上面的问题并非是 对 rocksdb的 所有提问,还有很多细节问题后续列出。需要提醒大家的是写入到简历中过的任何一个关键词都会引起熟悉该关键词的面试官的注意,随之而来的就是深度考察。 3. 分布式方向这个大方向其实是分布式领域的热门方向,毕竟分布式事务/共识算法 是分布式系统的分布式基石。 事务 分布式事务我并不懂,但是面试官想要了解的是个人对数据库事务的理解。我了解rocksdb , 所以可以用单机事务来作为补充了。😃 一般提到事务,肯定是有其特殊的应用场景,无论是对方做的TP/AP系统,或多或少都有一定的事务需求。这个方向 也是需要仔细准备的,当然,能够和项目一起准备的话那也没什么问题。 我这里补充的是一些事务的问题,可以扩展到分布式事务上(本质上因为有 rpc,分布式事务肯定复杂度会更好一些)。 简单说一下 对数据库 ACID的理解数据存储为什么需要有隔离性 ,常见的隔离级别有哪一些?你所了解的存储系统中(项目中)是如何实现这一些隔离级别的?(rocksdb的 WriteBatchWithIndex/SnapShot等 实现 rc/si)该项目中是如何解决事务并发问题的?解决的过程中遇到了哪一些问题?悲观事务中如何对key加锁? 如何发现 以及 避免死锁?乐观事务和悲观事务实现区别?(我的博客 Rocksdb 事务 中有完整实现原理的解析)单机事务和分布式事务 核心差异是?(跨机器级别的唯一性标识,时钟系统),NTP 时钟的问题,为什么会有这个问题?TSO/LC/HLC 各自的差异 以及 其应用场景,你们的场景在选择了 其中一个时钟方案时所作的取舍是什么?为什么 TrueTime 出来这么久,还是没有能够大面积实现推广,其中可能的技术难点是什么? (这个方向可以考察的细节可太多了,毕竟时钟系统时分布式事务的基石,对其业界各个实现方案的熟练掌握标识着你们的分布式事务方案设计是否有足够多的考量,细节可以参考时钟系统的设计原理)。热key 场景如何识别热key,对应的性能解决方案是?(可以自己想想)分布式事务的方案不懂,所以后续的分布式事务相关问题 都拒掉了。 共识算法 做过MIT 6.824 或者 tinykv的同学,这里可能会熟悉不少,不过还是会考察到很多工业级共识算法的实现的取舍。 了解哪一些共识算法?raft/zab, 可以简单介绍一下 raft的选举流程吗?raft的日志复制过程中 新加入的从节点发现自己的log-index 远小于主的log-index ,这两个节点如何进行log同步?这个过程期间raft 集群能否对外提供服务?如何缩短停服务的时间?对工业级raft的实现是否有了解,为什么会有 no-op日志?工业级raft的实现 如何提升raft的性能(multi-raft实现)?这里因为我个人的方向比较偏底层存储,上层并没有问太多的问题。 4. OS方向这个方向一般会伴随着项目中一起问,而且做存储的话时根本离不开os 的,所以os 相关的系统知识会有不少提问。 一个进程是如何知道自己要写哪一个文件的(从os的角度来看)?write 系统调用的原理(分别讲一下开启 direct 以及 关闭direct的链路),direct io 能够保证数据一定落盘?os的哪一层是做 io 聚合的,常用的调度算法以及其适用场景分别是什么?os 为什么需要通用块层和I/O调度层(屏蔽不同磁盘设备之间的差异)?介绍一下mmap的基本实现原理 以及 其应用场景,所谓的零拷贝如何借助mmap实现的?数据库存储场景是否适合使用mmap,谈谈你的理解?aio 和 io_uring 各自的实现原理 ?存在的问题 以及 其适用场景。常用的内存分配器是什么?为什么需要有内存分配器?其基本设计原理是什么样子的?为什么需要这么设计?如何评估一个项目需要内存分配器的接入,如果让你设计或者选择一个内存分配器,你会结合项目考虑哪一些维度?内存分配器所持有的内存是进程内存的哪一些区域,还有其他哪一些区域,动态库会放在哪里? |
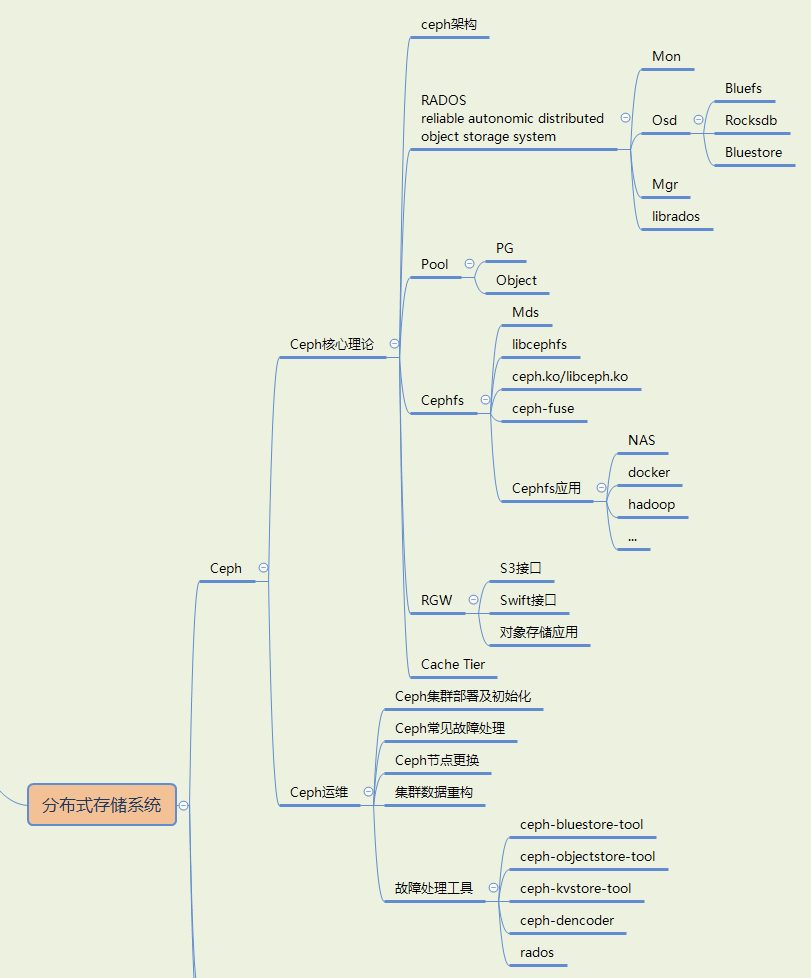 有了这样一个分支帮助你梳理知识,ceph方向只需要维护这一个分支就可以了(我列的不一定全,欢迎大家补充),从一个大的分类思考到一个小的分类,整个ceph的总结就像庖丁解牛一样,从架构到细节,不放过一个知识点。面试的时候无论面试官怎么问,自己大脑的知识是连城线的,也不会慌(当然前提是对ceph代码细节足够了解,有足够多的实践/源码修改经验 会更加泰然自若一些)。
有了这样一个分支帮助你梳理知识,ceph方向只需要维护这一个分支就可以了(我列的不一定全,欢迎大家补充),从一个大的分类思考到一个小的分类,整个ceph的总结就像庖丁解牛一样,从架构到细节,不放过一个知识点。面试的时候无论面试官怎么问,自己大脑的知识是连城线的,也不会慌(当然前提是对ceph代码细节足够了解,有足够多的实践/源码修改经验 会更加泰然自若一些)。【本文地址】